چگونه می توان از کتابخانه pandas در پایتون برای تجزیه و تحلیل داده های سری زمانی استفاده کرد؟ بیایید دریابیم.
کتابخانه pandas اغلب برای وارد کردن، مدیریت و تجزیه و تحلیل مجموعه داده ها در قالب های مختلف استفاده می شود. در این مقاله از آن برای تجزیه و تحلیل قیمت سهام مایکروسافت در سال های گذشته استفاده خواهیم کرد. همچنین خواهیم دید که چگونه میتوان کارهای اساسی مانند نمونهبرداری مجدد و تغییر زمان را با pandas انجام داد.
داده های سری زمانی چیست؟
داده های سری زمانی حاوی مقادیری هستند که به یک نوع از واحد زمانی وابسته هستند. موارد زیر همه نمونه هایی از داده های سری زمانی هستند:
- تعداد اقلام فروخته شده در هر ساعت در یک دوره 24 ساعته
- تعداد مسافرانی که در یک دوره یک ماهه سفر می کنند
- قیمت سهام در روز
در همه اینها، داده ها به واحدهای زمانی وابسته است. در یک نمودار، زمان در محور x و مقادیر داده مربوطه در محور y ارائه می شود.
دریافت داده ها
ما از یک مجموعه داده حاوی قیمت سهام مایکروسافت برای سالهای 2013 تا 2018 استفاده خواهیم کرد. این مجموعه داده را میتوان به صورت رایگان از YAHOO FINANCE دانلود کرد. ممکن است لازم باشد بازه زمانی را برای دانلود داده ها (که در قالب CSV است) انتخاب کنید.
وارد کردن کتابخانه های مورد نیاز
قبل از اینکه بتوانید مجموعه داده را به برنامه خود وارد کنید، باید کتابخانه های مورد نیاز را وارد کنید. برای این کار اسکریپت زیر را اجرا کنید.
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as pltاین اسکریپت کتابخانه های NumPy، pandas و matplotlib را وارد می کند. اینها کتابخانه های مورد نیاز برای اجرای اسکریپت های این مقاله هستند.
- برای یادگیری matplotlib میتوانید دوره آموزش Matplotlib را مطالعه کنید.
توجه: تمام اسکریپت های مجموعه داده با استفاده از ادیتور JUPYTER notebook برای پایتون اجرا شده اند.
وارد کردن و تجزیه و تحلیل مجموعه داده
برای وارد کردن مجموعه داده، از متد read_csv() از کتابخانه pandas استفاده می کنیم. اسکریپت زیر را اجرا کنید:
stock_data = pd.read_csv('E:/Datasets/MSFT.csv')برای اینکه ببینید مجموعه داده چگونه به نظر می رسد، می توانید از متد head() استفاده کنید. این متد پنج ردیف اول مجموعه داده را برمی گرداند.
stock_data.head()خروجی به شکل زیر است:
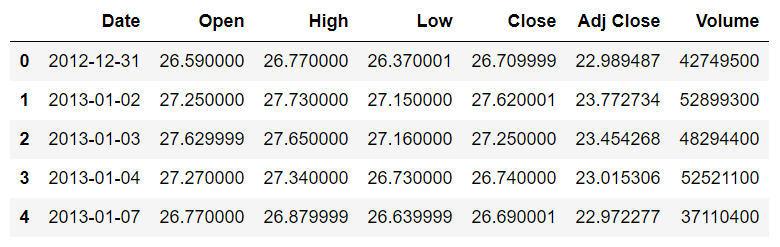
می بینید که مجموعه داده شامل تاریخ و قیمت های باز، بالا، پایین، بسته و تنظیم شده برای سهام مایکروسافت است. در حال حاضر، ستون Date به عنوان یک رشته ساده در نظر گرفته می شود. ما می خواهیم مقادیر موجود در ستون Date به عنوان شیء تاریخ در نظر گرفته شوند. برای این کار باید ستون Date را به نوع datetime تبدیل کنیم . اسکریپت زیر این کار را انجام می دهد:
stock_data['Date'] = stock_data['Date'].apply(pd.to_datetime)در نهایت، باید از ستون Date به عنوان یک ستون شاخص (index) استفاده کنیم، زیرا بقیه ستونها به مقادیر این ستون بستگی دارند. برای این کار اسکریپت زیر را اجرا کنید:
stock_data.set_index('Date',inplace=True)اگر دوباره از متد head() استفاده کنید، می بینید که Date مانند تصویر زیر مقادیر در ستون پررنگ هستند. این به این دلیل است که Date ستون اکنون به عنوان ستون شاخص در نظر گرفته می شود:
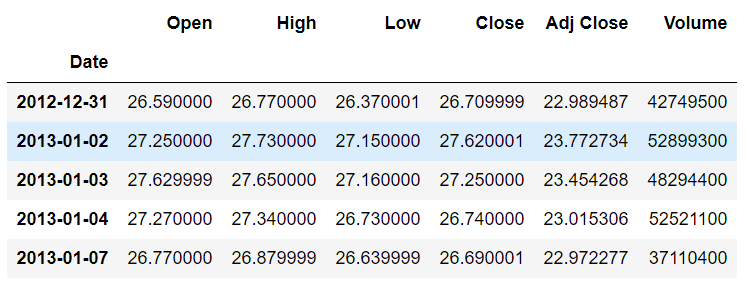
حال، بیایید مقادیر ستون Open را در برابر تاریخ رسم کنیم. برای این کار اسکریپت زیر را اجرا کنید:
plt.rcParams['figure.figsize'] = (10, 8) # افزایش سایز نمودار
stock_data['Open'].plot(grid = True)خروجی قیمت سهام افتتاحیه از ژانویه 2013 تا پایان سال 2017 را نشان می دهد:
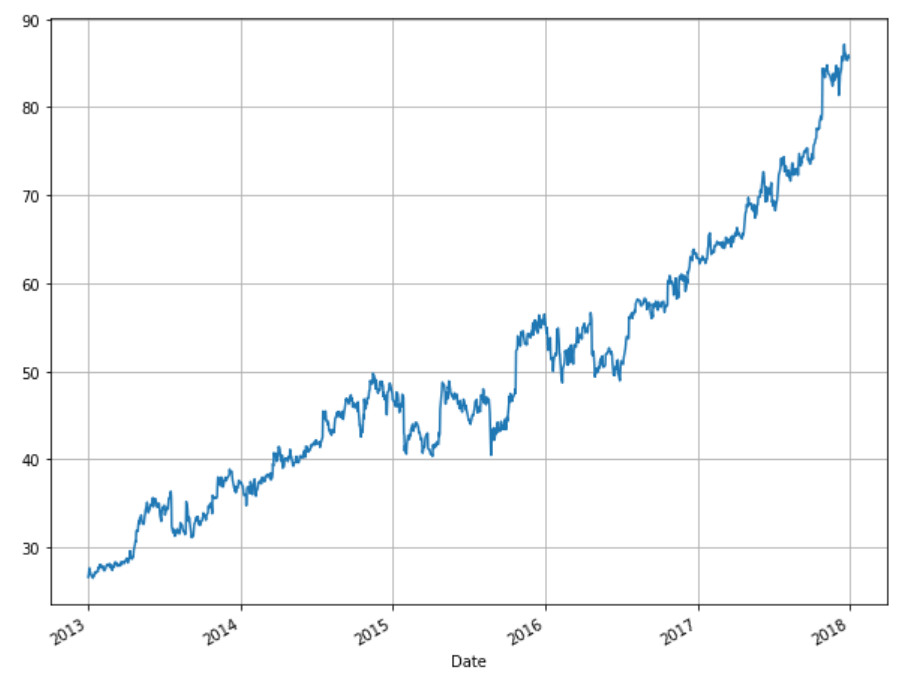
در مرحله بعد، از کتابخانه pandas برای نمونهبرداری مجدد زمان استفاده میکنیم.
نمونه گیری مجدد زمانی
نمونهگیری مجدد زمانی یعنی جمعآوری دادههای سری زمانی با توجه به دوره زمانی خاص یعنی برای هر هفته، یا هر ماه یا …. به طور پیش فرض، شما اطلاعات قیمت سهام را برای هر روز دارید. اگر بخواهید اطلاعات میانگین قیمت سهام برای هر سال را به دست آورید، چه؟ برای این کار می توانید از نمونه برداری مجدد از زمان استفاده کنید.
کتابخانه pandas دارای تابع resample() است که می تواند برای نمونه برداری مجدد زمان استفاده شود. تنها کاری که باید انجام دهید این است که یک افست برای ویژگی rule به همراه یک تابع تجمیع (مانند max، min، mean و غیره) تنظیم کنید.
دوره آموزشی مرتبط: دوره آموزش پروژه محور تحلیل داده در پایتون
در زیر برخی از افست هایی که می توانند به عنوان مقادیر برای ویژگی rule از تابع resample() استفاده شوند، آورده شده است:
W دوره هفتگی
M دوره ماهانه
Q دوره سه ماهه
A دوره سالانهلیست کامل مقادیر افست را می توان در اسناد pandas یافت.
اکنون تمام اطلاعاتی را که برای نمونهگیری مجدد زمان نیاز دارید در اختیار دارید. فرض کنید می خواهید میانگین قیمت سهام در هر سال را پیدا کنید. برای این کار اسکریپت زیر را اجرا کنید:
stock_data.resample(rule='A').mean()مقدار افست A مشخص می کند که می خواهید با توجه به سال نمونه برداری مجدد انجام دهید. تابع mean() مشخص می کند که می خواهید میانگین ارزش سهام را پیدا کنید.
خروجی به شکل زیر است:
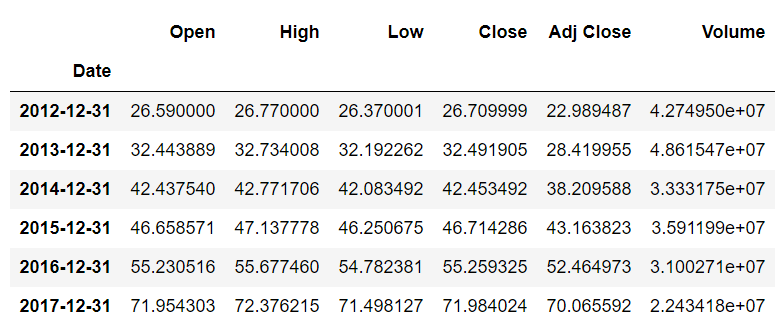
می بینید که مقدار Date ستون آخرین روز هر سال است. همه مقادیر دیگر، مقادیر میانگین کل آن سال هستند.
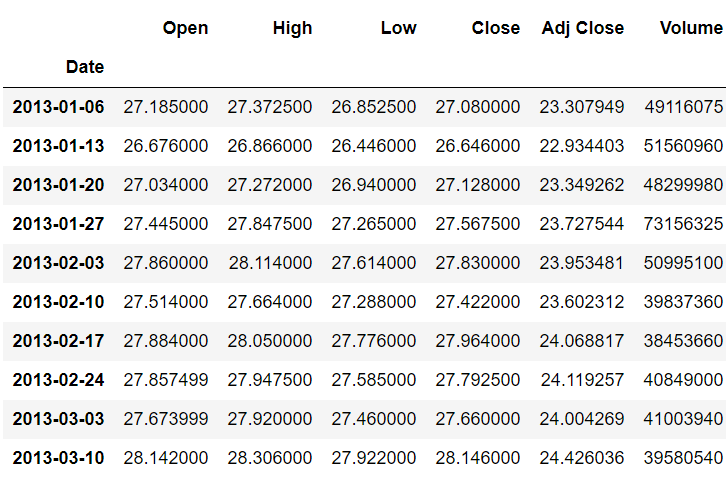
به طور مشابه، می توانید میانگین قیمت هفتگی سهام را با استفاده از اسکریپت زیر بیابید. (توجه: افست هفته “W” است.)
stock_data.resample(rule='W').mean()خروجی:
استفاده از نمونه برداری مجدد زمانی برای ترسیم نمودارها
همچنین می توانید نمودارهایی را برای یک ستون خاص با استفاده از نمونه گیری مجدد زمانی رسم کنید. به اسکریپت زیر نگاه کنید:
plt.rcParams['figure.figsize'] = (8, 6) # تنظیم سایز نمودار
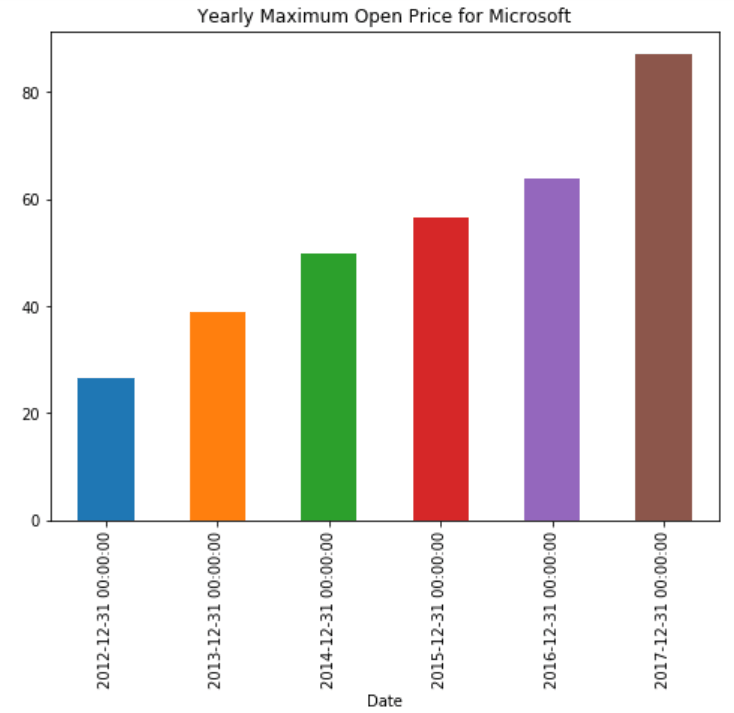
stock_data['Open'].resample('A').max().plot(kind='bar')
plt.title('Yearly Maximum Open Price for Microsoft')اسکریپت بالا نمودار میله ای را ترسیم می کند که حداکثر قیمت سالانه سهام را نشان می دهد. می بینید که به جای کل مجموعه داده، روش نمونه گیری مجدد فقط در ستون Open اعمال می شود. توابع max() و plot() با هم زنجیر می شوند تا 1) ابتدا حداکثر قیمت افتتاحیه را برای هر سال پیدا کند و 2) نمودار میله ای را رسم کند. ویژگی kind نوع نمودار را مشخص می کند. خروجی به شکل زیر است:
به طور مشابه، برای ترسیم حداکثر قیمت افتتاحیه سه ماهه، فقط مقدار افست را روی Q تنظیم می کنیم:
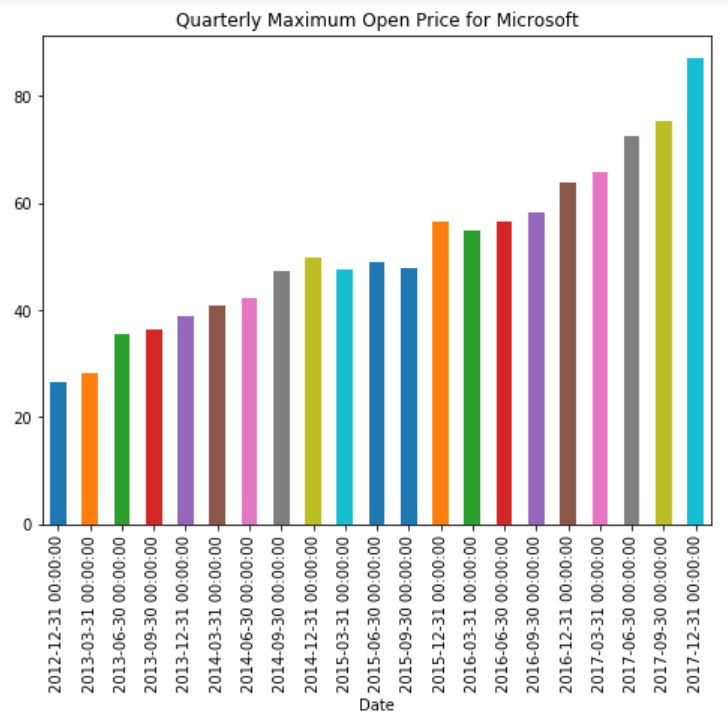
plt.rcParams['figure.figsize'] = (8, 6) # change plot size
stock_data['Open'].resample('Q').max().plot(kind='bar')
plt.title('Quarterly Maximum Open Price for Microsoft')اکنون می توانید حداکثر قیمت سهام افتتاحیه سه ماهه مایکروسافت را مشاهده کنید:
تغییر زمان
تغییر زمان به حرکت داده ها به جلو یا عقب در طول شاخص زمان اشاره دارد. بیایید ببینیم منظور ما از انتقال داده به جلو یا عقب چیست.
ابتدا، خواهیم دید که پنج سطر اول و پنج سطر آخر مجموعه داده ما با استفاده از توابع head() و tail() چگونه به نظر می رسند . تابع head() پنج ردیف اول مجموعه داده را نمایش می دهد، در حالی که تابع tail() پنج سطر آخر را نمایش می دهد.
اسکریپت های زیر را اجرا کنید:
stock_data.head()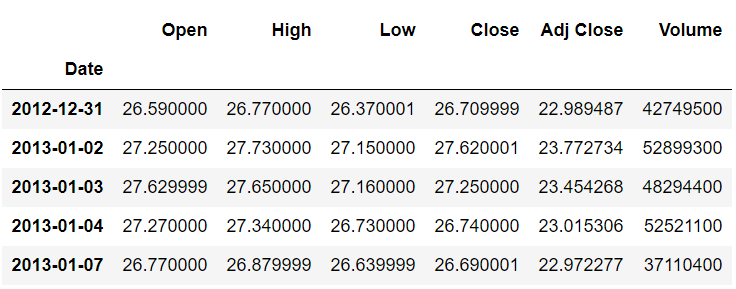
stock_data.tail()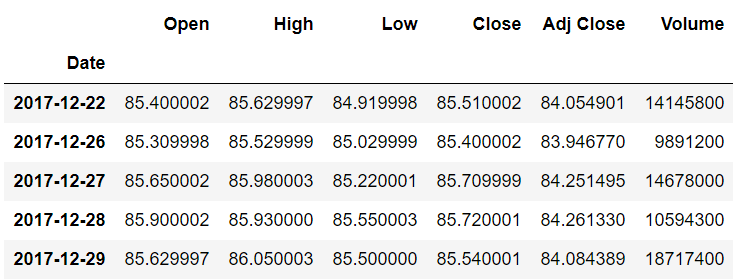
ما رکوردها را از سر و دم مجموعه داده چاپ کردیم زیرا وقتی بعداً داده ها را جابجا می کنیم، تفاوت بین داده های واقعی و جابجا شده را خواهیم دید.
جابجایی به جلو
برای جابجایی دادهها به جلو، کافی است تعداد ایندکسها به متد shift() ارسال کنید، مانند کد زیر:
stock_data.shift(1).head()اسکریپت بالا داده های ما را یک شاخص به جلو می برد، به این معنی که مقادیر ستون های Open , Close , Adjusted Close و Volume که قبلاً به رکورد N تعلق داشتند اکنون به رکورد N+1 تعلق دارند . خروجی به شکل زیر است:
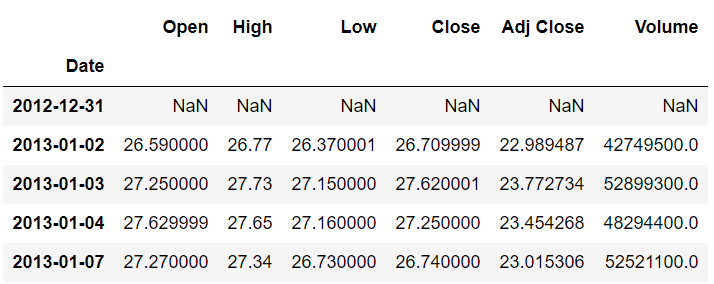
از خروجی می توانید ببینید که شاخص اول (31-12-2012) اکنون هیچ داده ای ندارد. شاخص دوم شامل رکوردهایی است که قبلاً به شاخص اول (1392-01-02) تعلق داشت.
به طور مشابه، در انتهای جدول، خواهید دید که آخرین شاخص (29-12-2017) اکنون حاوی رکوردهایی است که قبلاً به شاخص دوم به آخرین (28-12-2017) تعلق داشت. این در زیر نشان داده شده است:
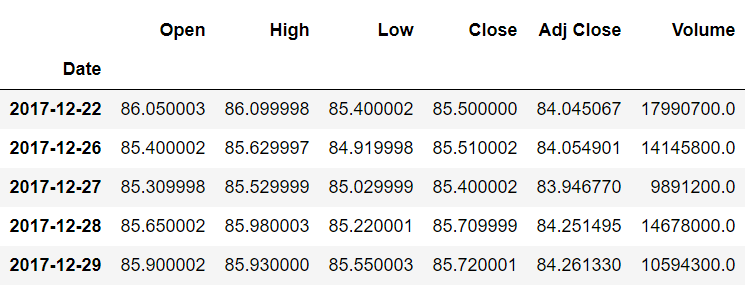
قبلاً، مقدار ستون Open 85.900002 متعلق به شاخص 2017-12-28 بود، اما پس از جابجایی یک شاخص به جلو، اکنون به سال 2017-12-29 تعلق دارد.
جابجایی به عقب
برای جابجایی داده ها به عقب، تعداد ایندکس ها را همراه با علامت منفی ارسال کنید. جابجایی یک شاخص به عقب به این معنی است که مقادیر ستون های Open , Close , Adjusted Close و Volume که قبلاً به رکورد N تعلق داشتند اکنون به رکورد N-1 تعلق دارند .
برای حرکت یک قدم به عقب، اسکریپت زیر را اجرا کنید:
stock_data.shift(-1).head()خروجی به شکل زیر است:
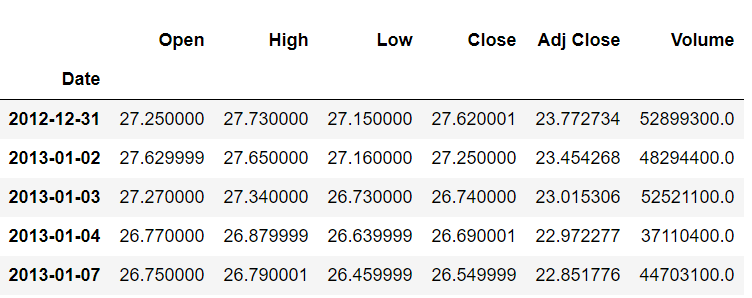
می بینیم که پس از حرکت یک شاخص به عقب، مقدار افتتاحیه 27.250000 متعلق به شاخص 2012-12-31 است. در حالیکه قبلاً متعلق به شاخص 2013-01-02 بود.
جابجایی داده ها با استفاده از افست زمان
در قسمت نمونه برداری مجدد از یک افست از جدول افست pandas برای تعیین بازه زمانی برای نمونه برداری مجدد استفاده کردیم. می توانیم از همان جدول افست برای جابجایی زمان نیز استفاده کنیم. برای انجام این کار، باید برای پارامتر های periods و freq از تابع ()tshift مقادیری تعیین کنیم. ویژگی period تعداد مراحل را مشخص می کند، و ویژگی freq اندازه هر مرحله را مشخص می کند. به عنوان مثال، اگر می خواهید داده های خود را دو هفته به جلو منتقل کنید، می توانید از تابع ()tshift به صورت زیر استفاده کنید:
stock_data.tshift(periods=2,freq='W').head()در خروجی، میبینید که دادهها دو هفته به جلو منتقل شدهاند:
درباره داده های سری زمانی در پایتون بیشتر بدانید
تجزیه و تحلیل سری های زمانی یکی از کارهای مهمی است که شما به عنوان یک کارشناس مالی ملزم به انجام آن هستید، همانند تجزیه و تحلیل پورتفولیو و فروش کوتاه. در این مقاله دیدید که چگونه می توان از کتابخانه pandas در پایتون برای تجسم داده های سری زمانی استفاده کرد. شما یاد گرفته اید که چگونه نمونه گیری زمان و جابجایی زمان را انجام دهید. با این حال، پایتون قابلیتهای تحلیل سریهای زمانی پیشرفتهتری را نیز ارائه میکند، مانند پیشبینی قیمتهای آتی سهام و انجام عملیات چرخشی و گسترش دادههای سری زمانی.
با سلام
برای رسم نمودار دو ستون از یک فایل ورودی csv که یکی عدد و دیگری str باشه چکار باید کرد؟
تشکر
سلام. از این کد می تونید استفاده کنید. از کتابخانه pandas برای باز کردن فایل csv و خواندن ستون ها استفاده می کنیم.