این ابزار در دو قالب ربات تلگرام و سایت ارائه میشود. بر اساس نیاز خود یکی از گزینه های زیر را انتخاب کنید:
ویژگی ها
- ✅ پشتیبانی از زبانهای فارسی، انگلیسی، عربی، ترکی، اسپانیایی و …
- ✅ دارای ربات تلگرام در کنار ابزار آنلاین برای تبدیل سریعتر ویس های تلگرامی
- ✅ امکان پردازش فایلهای طولانی (کاربران فایل هایی تا ۱۰ ساعت نیز با ربات تبدیل کرده اند)
- ✅ دقت بالا در تبدیل گفتار به متن، با استفاده از مدل حرفه ای گوگل
- ✅ رایگان برای فایل های زیر ۵ دقیقه (همچنین همیشه میتوانید ۵ دقیقه ابتدایی فایل های بزرگتر را به رایگان تست کنید)
- ✅ بسته اول: ۳۰ هزار تومان برای یک ساعت فایل، هرچه بسته بزرگتر شود، شامل تخفیف ویژه خواهد شد.
- ✅ امکان ویراستاری با AI بعد از تبدیل فایل
- ✅ با قابلیت دعوت از دوستان و دریافت شارژ رایگان
معرفی ابزار آنلاین و ربات تلگرام تبدیل فایل صوتی به متن ادروکا
ابزار آنلاین تبدیل ویس به متن و ربات تلگرامی audiofile_to_text_bot یک ابزار حرفهای برای تبدیل صوت به متن است که به شما امکان میدهد فایلهای صوتی و ویسهای خود را به متن تبدیل کنید، بدون نیاز به نرمافزارهای پیچیده و پردردسر. این ابزار از تکنولوژی Google Speech-to-Text بهره میبرد که دقت بالایی در تشخیص گفتار دارد و میتواند فایلهای صوتی طولانی را نیز پردازش کند.
ویژگیهای کلیدی این ابزار:
- ✅ پشتیبانی از زبانهای مختلف: امکان تبدیل صوت به متن در چندین زبان، از جمله فارسی و انگلیسی.
- ✅ بدون نیاز به نصب نرمافزار: تنها با استفاده از تلگرام، میتوانید فایلهای صوتی خود را به متن تبدیل کنید.
- ✅ امکان پردازش فایلهای طولانی: برخلاف بسیاری از ابزارها که محدودیت زمانی دارند، این ربات میتواند فایلهای صوتی بلند را نیز پردازش کند.
- ✅ دقت بالا در تبدیل گفتار به متن: این ربات از یکی از پیشرفتهترین موتورهای تبدیل گفتار به متن استفاده میکند که خروجی آن کمترین خطای ممکن را دارد.
- ✅ محاسبه دقیق هزینه و امکان تست رایگان: فایل های زیر 5 دقیقه رایگان هستند و همچنین همیشه میتوانید 5 دقیقه اول هر فایل را به صورت رایگان تست کنید تا اگر کیفیت مطلوب بود، برای تبدیل بیشتر، اکانت خود را شارژ نمایید.
این ربات برای چه کسانی مفید است؟
- 🔹 دانشجویان و پژوهشگران: برای تبدیل صوت کلاسها و جلسات دانشگاهی به متن.
- 🔹 روزنامهنگاران و تولیدکنندگان محتوا: برای مستندسازی مصاحبهها و جلسات.
- 🔹 کسبوکارها و تیمهای حرفهای: برای ذخیره و تحلیل مکالمات جلسات و وبینارها.
- 🔹 افرادی که فرصت گوش دادن به فایلهای صوتی را ندارند: اگر وقت ندارید که به ویسهای طولانی گوش دهید، این ربات در چند ثانیه متن آن را به شما ارائه میدهد!
راهنمای استفاده از ربات تلگرام تبدیل فایل صوتی به متن
استفاده از ربات تلگرامی audiofile_to_text_bot بسیار ساده است و در چند مرحله کوتاه میتوانید فایل صوتی یا ویس خود را به متن تبدیل کنید. در ادامه، نحوه استفاده از این ربات را مرحلهبهمرحله توضیح میدهیم.
۱. شروع کار با ربات
✅ ابتدا وارد تلگرام شده و به آیدی ربات [audiofile_to_text_bot] مراجعه کنید.
✅ دستور /start را ارسال کنید.
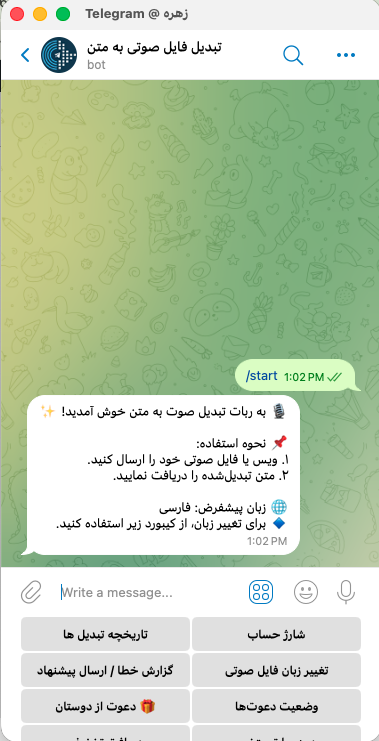
۲. ارسال فایل صوتی یا ویس
✅ پس از start بدون هیچ تنظیمات اضافی آماده استفاده است. در این مرحله فایل صوتی خود را به ربات ارسال کنید.
✅ فرمتهای پشتیبانیشده: ویس تلگرام، MP3، WAV، OGG و سایر فرمتهای رایج.
✅ زبان پیشفرض فارسی است. در صورتی که فایل شما با زمان دیگری است گزینه «🔄 تغییر زبان» را انتخاب کنید.
✅ مدت زمان فایل بررسی میشود و بر اساس میزان شارژ حساب یا تست رایگان تعیین میشود که آیا کل فایل پردازش خواهد شد یا فقط بخشی از آن.
✅ هزینه تبدیل پایه هر دقیقه فایل صوتی ۵۰۰ تومان است که هر چه بسته های بزرگتری را شارژ کنید، شامل تخفیف پلکانی خواهد شد.
چیزی که در مثال زیر میبیند، فایل ارسالی با فرمت m4a بوده و ۱ ساعت و ۵۴ دقیقه است. اگر موجودی کیف پول کافی میبود، فقط یک گزینه “🚀 شروع تبدیل” را داشتیم اما در مثال زیر، چون موجودی کیف پول کافی نیست، دو گزینه دیگر داریم:
- تبدیل رایگان n دقیقه اول
- تبدیل کل فایل
اگر موجودی صفر باشد، شما میتوانید ۵ دقیقه اول فایل را رایگان تبدیل کنید. در این مثال کاربر، ۱۵ دقیقه موجودی دارد که با ۵ دقیقه شارژ هدیه، میتواند ۲۰ دقیقه ابتدایی فایل را تبدیل کند. اما اگر بخواهید کل فایل را تبدیل کنید، باید گزینه «تبدیل کل فایل» را بزنید. در این صورت هزینه لازم برای مابقی فایل محاسبه شده، لینک درگاه پرداخت برای شما ارسال میشود و پس از پرداخت میتوانید روی دکمه ای که برای شما مهیا میشود، کلیک کرده و کل فایل را تبدیل کنید.
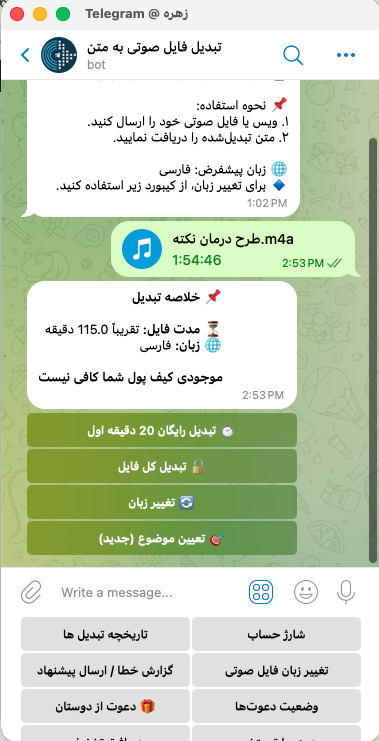
گزینه «تعیین موضوع» گزینه جدیدی است که شما را به سمت ربات تخصصی ما هدایت میکند که یک ربات جداگانه برای تبدیل فایل های تخصصی است.
۳. دریافت نتیجه تبدیل
- پس از ارسال، فایل شما در فرایند پردازش قرار میگیرد و در انتها متن استخراج شده، برای شما ارسال میشود.
- مسیر پیشرفت تبدیل به صورت درصد به شما نمایش داده میشود.
شارژ حساب برای استفاده از تخفیفات
در صورتی که برای هر فایل جداگانه پرداخت کنید، پرداخت شما شامل تخفیف نخواهد بود اما در صورتی که بسته های شارژ مشخص شده را خریداری کنید، بسته های بزرگتر به صورت پلکانی شامل تخفیف خواهند بود و اگر مصرف بالایی داشته باشید به شدت به صرفه خواهد شد. برای اینکار:
- در ربات دکمه “شارژ حساب” را بزنید.
- پس از انتخاب بسته مورد نظر، شما به صفحه پرداخت منتقل میشوید.
- بعد از پرداخت موفق، حساب شما بلافاصله شارژ شده و میتوانید به تبدیل فایلهای صوتی خود ادامه دهید.

📌 نکات مهم:
✔️ برای استفاده بهینه، همیشه ابتدا دستور /start را ارسال کنید.
✔️ در صورت بروز مشکل، میتوانید با ارسال /start فرآیند را مجدداً از ابتدا آغاز کنید.
✔️ در هر مرحله، در صورت نیاز به راهنمایی، میتوانید با پشتیبانی ربات تماس بگیرید.
ویژگی خاص: تبدیل فایلهای صوتی طولانی بدون محدودیت
یکی از مشکلات اصلی بسیاری از ابزارهای تبدیل صوت به متن، محدودیت در طول فایلهای صوتی است. اغلب این ابزارها فقط برای ویسهای کوتاه یا فایلهایی با چند دقیقه زمان مناسب هستند. اما ربات audiofile_to_text_bot این محدودیت را ندارد!
نمونه های تبدیل فایل صوتی به متن
در این بخش، چند نمونه از فایل های تبدیل شده با این ابزار و ربات آورده شده است. برای حفظ حقوق فایل ها، فقط از فایل های عمومی که در کانال های عمومی منتشر شده اند برای تست و ارائه نمونه این بخش استفاده کرده ایم:
نمونه ۱: ویس درس انتگرال
ویس ورودی:
لینک ویس در یک کانال تلگرام
متن خروجی:
نمونه 2: یک راه کست از کانال تلگرام مدیروب که به صورت ویس تلگرامی ضبط شده است
ویس ورودی:
متن خروجی:
نمونه 3: بخشی از مصاحبه دکتر andrew huberman با دکتر Laurie Santos
ویس ورودی:
متن خروجی:
مقایسه این ابزار با سایر ابزار های تبدیل ویس به متن
ابتدا ابزار های معروف دیگر را با هم بررسی کنیم و سپس با هم ببینیم که ابزار آنلاین و ربات تلگرام ادروکا چه برتری به آنها دارد:
ایبو (Eboo)
ایبو یک ابزار مناسب برای تبدیل فایل صوتی به متن است که از دقت بالا و پشتیبانی گستردهای از زبانهای مختلف برخوردار است. این ابزار به کاربران اجازه میدهد تا فایلهای صوتی خود را با فرمتهای رایج مانند MP3، WAV، M4A، و OGG به متن تبدیل کنند. تعرفه خدمات ایبو بهصورت دقیقهای محاسبه میشود و از 240 تا 300 تومان برای هر دقیقه است. این ابزار دارای امکاناتی همچون ویرایش مستقیم متن پس از تبدیل و پشتیبانی از API است که این ویژگیها به توسعهدهندگان کمک میکند تا این ابزار را به راحتی در پروژههای خود ادغام کنند. ایبو با رابط کاربری ساده و کاربرپسند خود استفاده از آن را برای تمامی کاربران، حتی کسانی که تجربه زیادی در استفاده از فناوریهای مشابه ندارند، آسان کرده است.
- پشتیبانی از فرمتها: MP3، WAV، M4A، OGG
- زبانهای پشتیبانیشده: بیش از 14 زبان مختلف
- تعرفه خدمات: 240 تا 300 تومان برای هر دقیقه
- امکانات: ویرایش مستقیم متن پس از تبدیل، پشتیبانی از API، رابط کاربری ساده و کاربرپسند
مقایسه با ادروکا:
- این ابزار تنها ۱ دقیقه تست رایگان اولیه دارد در حالیکه در ابزار ادروکا، تمام فایل های زیر ۵ دقیقه رایگان هستند و ۵ دقیقه ابتدایی بقیه فایل ها نیز همیشه به عنوان هدیه، رایگان محاسبه میشوند.
- این ابزار ربات تلگرامی یا اپلیکیشن دیگری ندارد و اگر فایلی در تلگرام داشته باشید، دوباره باید آپلود کنید
فارسآوا (Farsava)
فارسآوا یک ابزار هوش مصنوعی است که به کاربران امکان تبدیل گفتار به نوشتار را میدهد. این ابزار از فایلهای صوتی و ویدئویی پشتیبانی کرده و قابلیت تبدیل فایل صوتی به متن را با دقت بالا و با افزودن خودکار علائم نگارشی ارائه میدهد. فارسآوا برای کاربران جدید یک ساعت اعتبار رایگان فراهم کرده است و پس از آن بستههای مختلفی برای استفادههای بیشتر در دسترس هستند. یکی از ویژگیهای جذاب فارسآوا، امکان ساخت زیرنویس برای ویدئوها است که میتواند در تولید محتوای چندرسانهای کاربرد داشته باشد. این ابزار با تمرکز بر زبان فارسی طراحی شده و میتواند گفتارهای طولانی و پیچیده را بهخوبی به متن تبدیل کند، که این ویژگی آن را به یکی از بهترین انتخابها برای کاربران فارسیزبان تبدیل میکند.
- پشتیبانی از فرمتها: فایلهای صوتی و ویدئویی
- زبانهای پشتیبانیشده: فارسی
- تعرفه خدمات: یک ساعت رایگان، بستههای مختلف پس از آن
- امکانات: افزودن خودکار علائم نگارشی، ساخت زیرنویس، تشخیص دقیق گفتار
مقایسه با ادروکا:
- این ابزار تنها یکبار، یک ساعت تست رایگان اولیه دارد در حالیکه در ابزار ادروکا، تمام فایل های زیر ۵ دقیقه رایگان هستند و ۵ دقیقه ابتدایی بقیه فایل ها نیز همیشه به عنوان هدیه، رایگان محاسبه میشوند.
- این ابزار ربات تلگرامی یا اپلیکیشن دیگری ندارد و اگر فایلی در تلگرام داشته باشید، دوباره باید آپلود کنید
- فقط از فارسی پشتیبانی میکند
تایپو (Typeo)
تایپو یک ابزار برای تبدیل فایل صوتی به متن است که استفاده آسان و سریعی دارد. این ابزار روزانه امکان تایپ 200 کلمه رایگان را به کاربران ارائه میدهد و از فرمتهای مختلف صوتی پشتیبانی میکند. تایپو برای زبانهای مختلف از جمله فارسی، انگلیسی، فرانسوی و اسپانیایی طراحی شده است. از امکانات مهم این ابزار میتوان به ویرایش مستقیم متن پس از تبدیل و امکان ذخیره متن بهعنوان فایل ورد اشاره کرد. این ویژگیها تایپو را برای افرادی که نیاز به استخراج و ویرایش سریع متون از فایلهای صوتی دارند، به گزینهای جذاب تبدیل میکند. رابط کاربری ساده و دسترسی آسان، تایپو را به یکی از بهترین انتخابها برای کاربران تازهکار تبدیل کرده است.
- پشتیبانی از فرمتها: فرمتهای مختلف صوتی
- زبانهای پشتیبانیشده: فارسی، انگلیسی، فرانسوی، اسپانیایی
- تعرفه خدمات: 200 کلمه رایگان روزانه
- امکانات: ویرایش مستقیم متن، ذخیره بهعنوان فایل ورد، رابط کاربری ساده
مقایسه با ادروکا:
- هزینه بسته ها در این ابزار تقریباً دوبرابر ابزار و ربات تلگرام ادروکا است.
- این ابزار ربات تلگرامی یا اپلیکیشن دیگری ندارد و اگر فایلی در تلگرام داشته باشید، دوباره باید آپلود کنید.
- تنها ۵ دقیقه تست رایگان ارائه میدهد
ایاو تایپ (iotype)
ایاو تایپ یک ابزار با دقت بالا برای تبدیل فایلهای صوتی و ویس به متن است که از فرمتهای مختلف صوتی پشتیبانی میکند. این ابزار به دلیل دقت بالای خود در تبدیل صوت به متن و بازبینی متون توسط اپراتور، یکی از گزینههای مناسب برای متون تخصصی و فنی محسوب میشود. ایاو تایپ علاوه بر پشتیبانی از فرمتهای رایج صوتی مانند MP3، WAV، M4A، OGG، MP4، و MKV، از زبانهای فارسی، انگلیسی، و عربی نیز پشتیبانی میکند. یکی از ویژگیهای مفید این ابزار، امکان شخصیسازی واژگان و علائم است که دقت تبدیل را بیشتر میکند. همچنین پشتیبانی از API به توسعهدهندگان اجازه میدهد تا این ابزار را به راحتی در پروژههای خود ادغام کنند و از امکانات آن بهرهمند شوند.
- پشتیبانی از فرمتها: MP3، WAV، M4A، OGG، MP4، MKV
- زبانهای پشتیبانیشده: فارسی، انگلیسی، عربی
- تعرفه خدمات: بستههای ماهانه و سالانه، پرداخت دقیقهای
- امکانات: بازبینی متن توسط اپراتور، پشتیبانی از API، شخصیسازی واژگان و علائم
مقایسه با ادروکا:
- این ابزار هیچ تست رایگانی برای بخش تبدیل فایل به متن ارائه نمیدهد و هزینه بسته ها در این ابزار بیشتر از ابزار و ربات تلگرام ادروکا است
- این ابزار ربات تلگرامی ندارد و اگر فایلی در تلگرام داشته باشید، دوباره باید آپلود کنید.
چرا باید از ربات تلگرام برای تبدیل فایل صوتی به متن استفاده کنیم؟
تصور کنید در یک جلسه مهم شرکت کردهاید و نمیخواهید هیچ نکتهای را از دست بدهید. یا شاید بخواهید ویسهای طولانی دوستانتان را بدون نیاز به گوش دادن، در چند ثانیه به متن تبدیل کنید. در چنین شرایطی، ابزارهای سنتی کارایی چندانی ندارند. اما چرا تلگرام و چرا یک ربات تلگرامی؟
۱. همیشه در دسترس و بدون نیاز به نصب نرمافزار
برخلاف نرمافزارهای پیچیدهای که نیاز به دانلود و نصب دارند، ربات تلگرامی تبدیل صوت به متن بدون هیچگونه نصب و راهاندازی خاصی در دسترس شماست. کافی است تلگرام را باز کنید و فایل صوتی را برای ربات ارسال کنید؛ به همین سادگی!
۲. سرعت بالا در تبدیل صوت به متن
این ربات با استفاده از API قدرتمند Google Speech-to-Text فایلهای صوتی را با دقت بالا و در کوتاهترین زمان ممکن به متن تبدیل میکند.
۳. تبدیل فایلهای صوتی طولانی
یکی از نقاط ضعف بسیاری از ابزارهای تبدیل صوت به متن، محدودیت در طول فایلهای صوتی است. اما ربات audiofile_to_text_bot این محدودیت را ندارد و میتواند فایلهای بلند را نیز پردازش کند.
۴. دقت و پشتیبانی از زبانهای مختلف
این ربات از فناوری تشخیص گفتار پیشرفته استفاده میکند و دقت بالایی در تشخیص کلمات دارد. علاوه بر این، از زبانهای متعددی از جمله فارسی و انگلیسی پشتیبانی میکند.
۵. مقرونبهصرفه و امکان تست رایگان
در مقایسه با سایر ابزارهای پولی، این ربات یک گزینه اقتصادی محسوب میشود. کاربران میتوانند 5 دقیقه تست رایگان برای هر فایل دریافت کنند و سپس در صورت رضایت، حساب خود را شارژ کرده و از خدمات بیشتر بهرهمند شوند.
چگونه یک فایل صوتی طولانی را با این ربات به متن تبدیل کنیم؟
✅ کافی است فایل صوتی خود را برای ربات یا ابزار آنلاین ارسال کنید.
✅ ربات مدت زمان فایل را محاسبه کرده و شما را از زمان تقریبی پردازش مطلع میکند.
✅ بسته به میزان شارژ حساب، کل فایل یا بخشی از آن تبدیل میشود.
✅ پس از پردازش، متن بهصورت کامل و دقیق برای شما ارسال خواهد شد.
📌 نکته:
✔️ در صورتی که فایل شما بسیار طولانی باشد، ربات ممکن است متن را به بخشهای مختلف تقسیم کرده و ارسال کند تا خواندن و استفاده از آن راحتتر باشد.
✔️ اگر در حین پردازش فایلی طولانی، اینترنت شما قطع شود، نگران نباشید! ربات به کار خود ادامه داده و نتیجه را برای شما ارسال میکند.
هزینهها و نحوه پرداخت در ربات تبدیل صوت به متن
ربات تلگرام audiofile_to_text_bot یک سرویس مقرونبهصرفه برای تبدیل فایلهای صوتی به متن ارائه میدهد. کاربران میتوانند 5 دقیقه اول هر فایل را رایگان تست کنند و در صورت رضایت، حساب خود را شارژ کرده و از امکانات حرفهای ربات استفاده کنند.
۱. هزینه تبدیل فایلهای صوتی
💰 هزینه هر دقیقه تبدیل صوت به متن: ۵۰۰ تومان
🔹 با توجه به اینکه برخی فایلهای صوتی طولانی هستند، هزینه تبدیل به صورت دقیقهای محاسبه میشود.
🔹 اگر شارژ حساب شما کافی نباشد، ربات فقط بخشی از فایل را پردازش کرده و هشدار میدهد که برای تبدیل کامل، نیاز به شارژ حساب دارید.
۲. تبدیل رایگان فایل های کوتاه و تست رایگان 5 دقیقه اول هر فایل
✅ فایل های زیر 5 دقیقه، همیشه رایگان هستند!
🔹 برای فایل های طولانی تر که نیاز به شارژ دارند، میتوانید 5 دقیقه اول را رایگان تست کنید تا اگر کیفیت مطلوب بود، شارژ کنید.
۳. روشهای پرداخت و شارژ حساب
📌 اگر موجودی حساب شما صفر باشد یا تست رایگان تمام شده باشد، ربات دکمه “شارژ حساب” را نمایش میدهد.
📌 پس از کلیک روی این گزینه، چندین بسته پیشنهادی برای شارژ حساب نمایش داده میشود:

📌 نحوه پرداخت:
🔹 پس از انتخاب مبلغ، به صفحه پرداخت منتقل میشوید.
🔹 بعد از پرداخت موفق، حساب شما بهطور خودکار شارژ میشود و میتوانید بلافاصله به تبدیل فایلهای صوتی ادامه دهید.
۴. مشاهده موجودی و مدت زمان باقیمانده
💡 در هر لحظه میتوانید میزان شارژ و تعداد دقایق باقیمانده را مشاهده کنید.
💡 کافی است گزینه «شارژ حساب» را بزنید تا اطلاعات حساب شما نمایش داده شود.
۵. بازگشت هزینه در صورت بروز خطا
🔹 اگر به هر دلیلی فایل شما پردازش نشد، مبلغ مربوط به آن فایل به حساب شما بازگردانده میشود.
🔹 در صورت بروز مشکل، میتوانید با پشتیبانی ربات تماس بگیرید تا درخواست بررسی شود.
چرا هزینههای این ربات مقرونبهصرفه است؟
✅ در مقایسه با سایر سرویسهای پولی، این ربات قیمت مناسبی دارد و تنها بر اساس میزان استفاده شما هزینه کسر میشود.
✅ نیازی به خرید اشتراک ماهانه ندارید؛ فقط هر زمان که نیاز داشتید، حساب خود را شارژ کرده و استفاده کنید.
✅ بدون تبلیغات و محدودیتهای آزاردهنده – تمام تمرکز این ربات روی ارائه بهترین کیفیت تبدیل صوت به متن است.
کاربردهای تبدیل صوت به متن: این ربات چگونه به شما کمک میکند؟
تبدیل فایلهای صوتی به متن میتواند در بسیاری از زمینهها کاربردی باشد. فرقی نمیکند که دانشجو باشید، تولیدکننده محتوا، روزنامهنگار یا حتی فردی که فرصت گوش دادن به ویسهای طولانی را ندارد؛ ربات تلگرام audiofile_to_text_bot میتواند کار شما را سادهتر کند! در ادامه، برخی از مهمترین کاربردهای این ربات را بررسی میکنیم.
۱. برای دانشجویان و اساتید: تبدیل کلاسهای درسی و سخنرانیها به متن
🎓 آیا در کلاسهای دانشگاهی شرکت میکنید و فرصت یادداشتبرداری ندارید؟
🎓 آیا میخواهید محتوای سخنرانیها و جلسات علمی را به متن تبدیل کنید؟
✅ با استفاده از این ربات میتوانید فایل ضبطشده کلاسها را ارسال کنید و متن آماده آن را دریافت کنید.
✅ دیگر نیازی نیست ساعتها وقت بگذارید و به فایلهای صوتی گوش دهید؛ این ربات همه چیز را به متن تبدیل کرده و آماده استفاده به شما تحویل میدهد!
۲. برای روزنامهنگاران و محققان: مستندسازی مصاحبهها و تحقیقات
📝 آیا روزنامهنگار یا محقق هستید و مصاحبههای زیادی انجام میدهید؟
📝 آیا میخواهید به جای گوش دادن به فایلهای صوتی، متن آماده مصاحبهها را داشته باشید؟
✅ این ربات فایلهای صوتی مصاحبهها را پردازش کرده و متن دقیق آنها را به شما ارائه میدهد.
✅ دیگر نیازی نیست برای نوشتن گزارش یا مقاله، چندین بار به صوتها گوش دهید!
۳. برای تولیدکنندگان محتوا: تبدیل ویس به متن برای بلاگ و ویدیوها
📢 آیا ایدههای خود را ابتدا به صورت ویس ضبط میکنید؟
📢 آیا میخواهید متن ویدیوی خود را برای زیرنویس یا وبلاگ آماده کنید؟
✅ بسیاری از تولیدکنندگان محتوا ایدههای خود را ابتدا بهصورت صوت ضبط میکنند و سپس به متن تبدیل میکنند.
✅ با استفاده از این ربات، میتوانید بدون تایپ کردن، ویسهای خود را به متن تبدیل کرده و از آنها برای نوشتن مقاله، وبلاگ یا متن ویدیوهای خود استفاده کنید.
۴. برای مدیران و تیمهای کاری: مستندسازی جلسات و وبینارها
📊 آیا در جلسات کاری و کنفرانسهای آنلاین شرکت میکنید؟
📊 آیا میخواهید محتوای جلسات را به متن تبدیل کرده و در اختیار همکاران خود بگذارید؟
✅ کافی است فایل ضبطشده جلسات کاری خود را برای ربات ارسال کنید، تا متن آن را دریافت کنید.
✅ این روش باعث میشود تیم شما همیشه به محتوای جلسات دسترسی داشته باشد و بهرهوری افزایش یابد!
۵. برای افرادی که فرصت گوش دادن به فایلهای صوتی را ندارند
⏳ آیا ویسهای طولانی دوستان و همکاران شما وقت زیادی از شما میگیرد؟
⏳ آیا میخواهید بدون گوش دادن، محتوای صوتی پیامهای دریافتی را در چند ثانیه بخوانید؟
✅ کافی است ویسهای طولانی را به این ربات ارسال کنید و متن آنها را در چند ثانیه دریافت کنید.
✅ این روش مخصوصاً برای افرادی که زمان کافی برای گوش دادن به ویسها ندارند، فوقالعاده کاربردی است!
آموزش های مربوط به برنامه نویسان
اگر برنامه نویس هستید و میخواهید از ابزار های متن باز برای تبدیل فایل صوتی به متن استفاده کنید، میتوانید از ابزارهای متنباز پایتون مانند Vosk و Whisper استفاده کنید. این ابزارها بهصورت رایگان در دسترس هستند و به راحتی روی سیستم شما نصب میشوند.
- Vosk: یک کتابخانه تشخیص گفتار آفلاین است که از زبانهای مختلف پشتیبانی میکند و به راحتی میتوانید آن را با
pip install voskنصب کنید. Vosk از منابع سیستمی کمی استفاده میکند و میتواند بهصورت آفلاین و با دقت بالا صوت را به متن تبدیل کند. - Whisper: توسط OpenAI توسعه داده شده و با استفاده از
pip install openai-whisperقابل نصب است. این ابزار از مدلهای یادگیری عمیق برای تشخیص گفتار با دقت بالا استفاده میکند و از زبانهای مختلف پشتیبانی میکند. Whisper به دلیل استفاده از مدلهای بزرگ، دقت بسیار خوبی در تبدیل گفتار به متن دارد و میتواند برای کاربردهای متنوعی مورد استفاده قرار گیرد.
آموزش عملی استفاده از کتابخانههای پایتون برای تبدیل فایل صوتی به متن
در این بخش به شما نشان میدهیم چگونه از دو کتابخانه Vosk و Whisper به صورت عملی برای تبدیل صوت به متن استفاده کنید. هر دو کتابخانه به راحتی قابل نصب و استفاده هستند و نیازی به تخصص زیاد در برنامهنویسی ندارند. البته بهتر است اول یک آموزش سریع پایتون ببینید تا با کد های اولیه آشنایی داشته باشید.
مقاله مرتبط : پایتون چیست؟ همه چیزهایی که باید درباره پایتون بدانید
1. آموزش استفاده از Vosk
Vosk یک کتابخانه آفلاین برای تشخیص گفتار است که از زبانهای مختلف پشتیبانی میکند. برای استفاده از این کتابخانه مراحل زیر را دنبال کنید:
گام 1: نصب Vosk
ابتدا باید کتابخانه Vosk را نصب کنید. برای این کار، از دستور زیر استفاده کنید:
pip install vosk
همچنین نیاز دارید ffmpeg را نصب کنید تا بتوانید فایلهای صوتی را به درستی پردازش کنید:
- در ویندوز میتوانید ffmpeg را از وبسایت رسمی دانلود و نصب کنید.
- در لینوکس:
sudo apt install ffmpeg
گام 2: دانلود مدل زبان
Vosk برای کارکرد نیاز به مدلهای زبان دارد. مدلها را میتوانید از صفحه مدلهای Vosk دانلود کنید. فایل مدل را در پوشهای از سیستم خود قرار دهید.
گام 3: نوشتن کد برای تبدیل صوت به متن
در این گام، یک اسکریپت پایتون مینویسیم که فایل صوتی را به متن تبدیل کند:
from vosk import Model, KaldiRecognizer
import wave
import json
# بارگذاری مدل زبان
model = Model("مسیر_فایل_مدل")
# باز کردن فایل صوتی
wf = wave.open("مسیر_فایل_صوتی.wav", "rb")
# بررسی فرمت فایل صوتی
if wf.getnchannels() != 1 or wf.getsampwidth() != 2 or wf.getframerate() not in [8000, 16000]:
print("فایل صوتی باید تککاناله و با نرخ نمونهبرداری 8000 یا 16000 هرتز باشد")
exit(1)
rec = KaldiRecognizer(model, wf.getframerate())
while True:
data = wf.readframes(4000)
if len(data) == 0:
break
if rec.AcceptWaveform(data):
result = json.loads(rec.Result())
print(result.get('text'))
# متن نهایی
final_result = json.loads(rec.FinalResult())
print(final_result.get('text'))
اگر به ساخت ابزارهای آنلاین علاقه دارید، توصیه می کنم مقاله چطور با هزینه پایین، ابزار های آنلاین خود را توسعه دهیم؟ را نیز مطالعه کنید.
2. آموزش استفاده از Whisper
Whisper یک ابزار هوش مصنوعی پیشرفته است که توسط OpenAI توسعه داده شده و برای تشخیص گفتار با دقت بالا طراحی شده است.
گام 1: نصب Whisper
ابتدا باید کتابخانه Whisper را نصب کنید:
pip install openai-whisper
همچنین به ffmpeg نیاز خواهید داشت، بنابراین مانند مرحله Vosk، آن را نصب کنید.
گام 2: نوشتن کد برای تبدیل صوت به متن
پس از نصب، میتوانید از کد زیر برای تبدیل فایل صوتی به متن استفاده کنید:
import whisper
# بارگذاری مدل
model = whisper.load_model("base")
# تبدیل فایل صوتی به متن
result = model.transcribe("مسیر_فایل_صوتی.mp3")
print(result["text"])
نکات مهم:
- انتخاب مدل: Whisper دارای مدلهای مختلفی است که از نظر اندازه و دقت متفاوت هستند، مانند
tiny,base,small,medium, وlarge. هر چه مدل بزرگتر باشد، دقت بالاتری دارد اما نیاز به منابع محاسباتی بیشتری دارد. - استفاده از GPU: اگر سیستم شما دارای کارت گرافیک است، میتوانید برای تسریع فرآیند از GPU استفاده کنید. برای این کار، کافی است پارامتر
deviceرا به “cuda” تنظیم کنید:model = whisper.load_model("base", device="cuda")
با دنبال کردن این مراحل، میتوانید به راحتی از ابزارهای متنباز پایتون برای تبدیل فایل صوتی به متن استفاده کنید و نیازهای خود را بهصورت رایگان و کارآمد برآورده کنید.
ویراستاری متن با هوش مصنوعی پس از تبدیل فایل صوتی به متن
برای ویراستاری متن تبدیل شده با هوش مصنوعی، میتوانید از ابزارهای مختلف استفاده کنید که قابلیت اصلاح متن، تشخیص اشتباهات گرامری و سبک نوشتاری، و حتی بازنویسی آن را دارند:
مراحل ویراستاری با هوش مصنوعی:
- استفاده از ابزارهای آنلاین:
- Grammarly: این ابزار به شما کمک میکند تا اشتباهات گرامری، املایی، و سبک نوشتاری را اصلاح کنید.
- Quillbot: برای بازنویسی متن و بهبود وضوح و انسجام آن بسیار مفید است.
- استفاده از مدلهای زبان هوش مصنوعی:
- مدلهای پیشرفتهای مانند GPT-3 یا ChatGPT (مثل همین مدل که در حال صحبت با آن هستید) میتوانند به شما در ویرایش متن کمک کنند. کافیست متن را به هوش مصنوعی وارد کنید و درخواست ویرایش بدهید.
- پیشپردازش با مدلهای پایتون:
- اگر دسترسی به پایتون دارید، میتوانید از کتابخانههایی مانند TextBlob یا LanguageTool استفاده کنید که قابلیت تشخیص و اصلاح خطاهای متنی را دارند.
مثال استفاده از پایتون:
برای مثال با استفاده از LanguageTool:
import language_tool_python
tool = language_tool_python.LanguageTool('fa') # پشتیبانی از زبان فارسی
text = "این یک متنی است که احتمالا دارای خطاهایی گرامری باشد."
matches = tool.check(text)
for match in matches:
print(match)
این کد به شما خطاهای موجود در متن را نشان میدهد و پیشنهادهای بهبود ارائه میدهد.
نکات مهم:
- سازگاری با زبان: ابزارهایی که استفاده میکنید باید از زبانی که متن در آن نوشته شده پشتیبانی کنند، بهخصوص اگر زبان فارسی باشد.
- تنظیمات هوش مصنوعی: مدلهای هوش مصنوعی قابلیت تنظیم دارند و میتوانند بر اساس نوع محتوا (رسمی یا غیررسمی) تنظیم شوند تا اصلاحات دقیقتر انجام دهند.
این روشها به شما کمک میکنند که پس از تبدیل صوت به متن، آن را به صورتی دقیق و روان ویرایش کنید و بهبود ببخشید.
سؤالات متداول
از چه مدلی برای تبدیل ویس به متن استفاده شده است؟
در این ربات از مدل Google Speech-to-Text برای تبدیل ویس به متن استفاده میشود و پس از آن از هوش مصنوعی deepseek برای ویراستاری (در صورت درخواست) استفاده میشود.
هزینه تبدیل فایل صوتی به متن چقدر است؟
فایل های زیر ۵ دقیقه رایگان هستند. در فایل های بزرگتر، ۵ دقیقه اول به صورت هدیه محاسبه میشود و مابقی آن، هر دقیقه حدود ۵۰۰ تومان است. هرچه بسته های بزرگتری شارژ شود، هزینه هر دقیقه پایین می آید. مثلاً در بسته ۱ ساعته که ۳۰ هزار تومان است هر دقیقه معادل ۵۰۰ تومان است اما در بسته بعدی که ۲ ساعته و ۵۰ هزار تومان است هر دقیقه معادل ۴۱۶ تومان میشود و به همین شکل هر چه حجم بسته ای که یکجا خریداری میکنید بالاتر برود، شامل تخفیف پلکانی خواهد شد. مثلاً در بسته ۵۰۰ هزارتومانی که معادل ۲۷.۷ ساعت است، هر دقیقه معادل ۳۰۰ تومان خواهد شد.
آیا شارژ حساب، تاریخ انقضا دارد؟
خیر، هر بار به اندازه طول فایل صوتی شما، از موجودی حسابتان کسر میشود و تا زمانی که دوباره بخواهید از ربات استفاده کنید، بدون محدودیت زمانی، مانده شارژ در حساب شما باقی خواهد ماند.
چطور میتوانیم شارژ رایگان دریافت کنیم؟
ما اخیراً به تقاضای افرادی که مشکلاتی در پرداخت هزینه ها داشتند، بخش «دعوت از دوستان» را راه اندازی کردیم. در این بخش یک پیام شامل لینک دعوت اختصاصی شما، برایتان ارسال میشود. با ارسال این پیام در گروه ها یا برای دوستان خود، اگر شخصی از طریق لینک اختصاصی شما وارد ربات شده و اولین تبدیل خود (حتی یک تبدیل رایگان زیر ۵ دقیقه) را انجام دهد، هم برای شما و هم برای دوستتان ۱۰ دقیقه به موجودی حسابتان اضافه خواهد شد. مثلاً در صورتی که یک فایل ۱ ساعته داشته باشید، میتوانید با دعوت از ۶ نفر، به صورت رایگان فایل خود را تبدیل کنید.
چه محدودیت هایی در مورد حجم و زمان فایل صوتی وجود دارد؟
هیچ محدودیتی از نظر حجم و زمان فایل ارسالی شما وجود ندارد.
حریم خصوصی فایل های کاربران به چه شکل مدیریت میشود؟
فایل های شما در هیچ جا ذخیره نخواهد شد. فایلی که در تلگرام ارسال میکنید، مستقیماً به مدل تبدیل فایل صوتی به متن ارسال میشود و فقط متن خروجی آن در دیتابیس ما ذخیره میشود تا هر زمان که خواستید بتوانید از طریق بخش تاریخچه ها به آن دسترسی داشته باشید.
مدت زمان پردازش فایلهای طولانی چقدر است؟
📌 فایلهای کوتاه (زیر ۵ دقیقه): معمولاً کمتر از یک دقیقه پردازش میشوند.
📌 فایلهای متوسط (۵ تا ۳۰ دقیقه): بسته به طول فایل، چند دقیقه طول میکشد.
📌 فایلهای طولانی (۳۰ دقیقه تا چند ساعت): این ربات میتواند فایلهای چندساعته را نیز پردازش کند، اما زمان تبدیل ممکن است حدود یک ساعت طول بکشد.
خیلی کاربردیه، مخصوصاً که توی تلگرامه و نیازی به نصب نرمافزار نداره. یه سوال داشتم، آیا امکانش هست که نتیجه تبدیلشده رو با فرمت PDF دریافت کنیم؟
بله به زودی امکان دریافت نتیجه در قالب فایل متنی اضافه میشه.
اینکه از API گوگل استفاده میکنه یه مزیت خیلی بزرگه، ولی کاش امکان شخصیسازی هم داشت، مثلا اینکه بعضی از اصطلاحات خاص رو بتونیم بهش یاد بدیم که درست تشخیص بده.